Using BigQuery Without Breaking the Bank
The closer you look at something, the more interesting it gets. That’s probably why I love it when I’m able to pore through large amounts of data related to a topic that interests me. You keep twisting and turning it enough, and you’ll eventually start to uncover fascinating trends and insights that weren’t apparent on the surface.
Hence, why I’m a big fan of BigQuery.
You can use it for your own private data, and I’ve worked at or with organizations that did, but there is also a wealth of public datasets available for you to dig into. I spend 90% of my time querying either the HTTP Archive or the Chrome User Experience Report (CrUX) data. Typically, I’m looking for performance trends, doing some level of competitive comparison, or digging through data for a company that doesn’t yet have a proper real-user monitoring (RUM) solution in place. But I’ve also dug into data from Libraries.io, GitHub, Stack Overflow, and World Bank, for example. There are more than enough public datasets to keep any curious individual busy for quite a while.
One of the great things about the BigQuery platform is how well it handles massive datasets and queries that can be incredibly computationally intensive. As someone who hasn’t had to write SQL as part of my job for at least 10 years, maybe longer, that raw power comes in handy as it makes up for my lack of efficient queries.
One thing that it doesn’t hide, though, is the cost. If you’re constantly querying BigQuery, you can end up with a pretty hefty bill fairly quickly.
Jeremy Wagner mentioned being concerned about this, and it’s something I was worried about when I first started playing around with it as well.
I’m no expert, but I do have a handful of tips for folks who maybe want to start digging into these datasets on their own but are wary of wracking up a big bill.
Don’t set up billing
If you’re just starting fresh, don’t even bother to set up billing yet. The free tier provides you with 1TB of query data each month. While it’s easier to burn through that than you might think, it’s also not a trivial amount.
If you stick with the free tier, when you exhaust your limits, BigQuery will fail to execute your next query and tell you you need to setup billing instead. It’s a safe way to play around, knowing that you aren’t going to be charged unless you explicitly decide to level up.
Set a budget
If you have moved beyond the free tier and your payment information is already set, then the next best thing you can do is use the different budgeting features BigQuery provides.
For each individual query, you can set a “maximum bytes billed” limit. If your query is going to exceed that limit, the query won’t run, and you won’t be charged. Instead, you’ll be told your limit is going to be exceeded. To run it successfully, you’d have to first up the budget or remove it entirely.
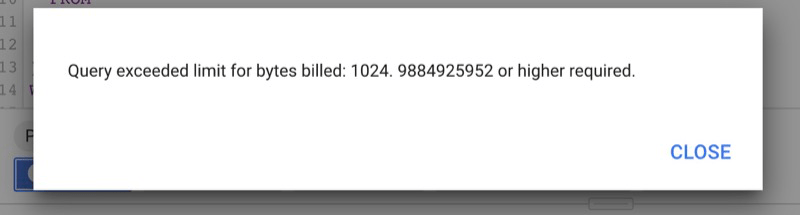
With a maximum bytes billed limit set on a query, the query will fail without charge if it will exceed that data limit.
You can also set a budget for the month as a whole. You can then set a few thresholds (BigQuery will default to 50%, 90%, and 100%), each of which will trigger an alert (like an email) warning you that they’ve been reached.
So, let’s say you set a monthly budget of $20. With alerts in place, you would be emailed as soon as you hit $10, again when you hit $18, and the once more when you hit your $20 budget. With these in place, you can rest easy knowing you aren’t going to be surprised with an obnoxiously high bill.
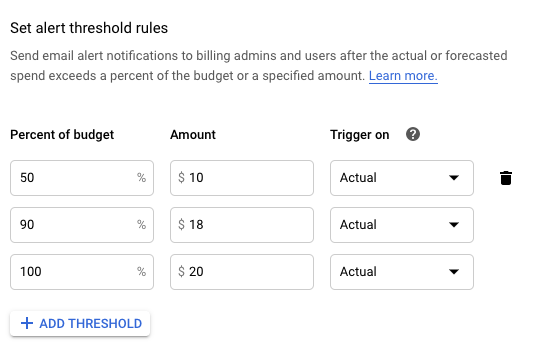
BigQuery lets you set a monthly budget, with different thresholds so you can be alerted as you get closer to using your budget.
Use BigQuery Mate for Query Cost Estimates

If you use Chrome, you can use BigQuery Mate to keep you informed of the anticipated cost of a query before you ever run it. BigQuery already tells you how much data you’re going to use in a given query. This extension adds the cost as well (something BigQuery should probably just do by default).
If you don’t use Chrome or don’t want to install the extension, you can also use Google’s cost calculator. It works, but it’s certainly a more manual and clunky process.
Test against smaller tables first, if possible
Some datasets have numerous tables that represent the data, just sliced differently.
For example, the CrUX data is contained in one massive table, as well as broken up into smaller tables for each country’s traffic. The structure, however, is identical.
When I’m writing a new query against CrUX data, and I know it’s gonna take some tweaking to get it right, I’ll pick a country table to query against instead. That way I’m using less data on all my experiments. When I’ve got the query returning the data I’m after in the format I want, that’s when I’ll go back to the main table to query the aggregate data.
If there aren’t smaller tables, make them
For other datasets, the smaller tables don’t exist, but you can make your own.
For example, I was recently querying HTTP Archive data to find connections between JavaScript framework usage and performance metrics. Instead of running my queries against the main tables over and over, I ran a query to find all the URL’s that were using one of the frameworks I wasn interested in. Then I grabbed all the data for those URL’s and dumped it into a separate table.
From there, every query could be run against this table containing only the data that was relevant for what I was investigating. The impact was huge. One query which would have gone through 9.2GB of data had I queried CrUX directly instead ended up using only 826MB of data when I queried the subset I created.
Plenty more, I’m sure
This is far from an exhaustive list of tips or advice, and I’m certain someone who spends more time than I do in BigQuery (or who actually knows what they’re doing in SQL) would have plenty more to add, but these have all been enough to make me really comfortable hopping into BigQuery whenever I think there might be something interesting to pull out.