How Fast Is Amp Really?
AMP has caused quite the stir from a philosophical perspective, but the technology hasn’t received as close of a look. A few weeks ago, Ferdy Christant wrote about the unfair advantage being given to AMP content through preloading. This got me wondering: how well does AMP really perform. I’ve seen folks, like Ferdy, analyze one or two pages, but I hadn’t seen anything looking at the broader picture…yet.
Evaluating the effectiveness of AMP from a performance standpoint is actually a little less straightforward than it sounds. You have to consider at least four different contexts:
- How well does AMP perform in the context of Google search?
- How well does the AMP library perform when used as a standalone framework?
- How well does AMP perform when the library is served using the AMP cache?
- How well does AMP perform compared to the canonical article?
How well does AMP perform in the context of Google search?
As Ferdy pointed out, when you click through to an AMP article from Google Search, it loads instantly—AMP’s little lightning bolt icon seems more than appropriate. But what you don’t see is that Google gets that instantaneous loading by actively preloading AMP documents in the background.
In the case of the search carousel, it’s literally an iframe that gets populated with the entirety of the AMP document. If you do end up clicking on that AMP page, it’s already been downloaded in the background and as a result, it displays right away.
In the context of Google search, then, AMP performs remarkably well. Then again, so would any page that was preloaded in the background before you navigated to it. The only performance benefit AMP has in this context is the headstart that Google gives it.
In other words, evaluating AMP’s performance based on how those pages load in search results tells us nothing about the effectiveness of AMP itself, but rather the effectiveness of preloading content.
How well does the AMP library perform when used as a standalone framework?
In Ferdy’s post, he analyzed a page from Scientas. He discovered that without the preloading, it’s far from instant. On a simulated 3G connection, the Scientas AMP article presents you with a blank white screen for 3.3 seconds.
Now, you might be thinking, that’s just one single page. There’s a lot of variability and it’s possible Scientas is a one-off example. Those are fair concerns so let’s dig a little deeper.
The first thing I did was browse the news. I don’t recommend this to anyone, but there was no way around it.
Anytime I found an AMP article, I dropped the URL in a spreadsheet. It didn’t matter what the topic was or who the publisher was: if it was AMP, it got included. The only filtering I did was to ensure that I tested no more than two URL’s from any one domain.
In the end, after that filtering, I came up with a list of 50 different AMP articles. I ran these through WebPageTest over a simulated 3G connection using a Nexus 5. Each page was built with AMP, but each page was also loaded from the origin server for this test.
AMP is comprised of three basic parts:
- AMP HTML
- AMP JS
- AMP Cache
When we talk about the AMP library, we’re talking about AMP JS and AMP HTML combined. AMP HTML is both a subset of HTML (there are restrictions on what you can and can’t use) and an augmentation of it (AMP HTML includes a number of custom AMP components and properties). AMP JS is the library that is used to give you those custom elements as well as handles a variety of optimizations for AMP-based documents. Since the foundation is HTML, CSS, and JS, you can absolutely build a document using the AMP library without using the Google AMP Cache.
The AMP library is supposed to help ensure a certain level of consistency with regards to performance. It does this job well, for the most part.
The bulk of the pages test landed within a reasonable range of each other. There was, however, some deviance on both ends of the spectrum: the minimum values were pretty low and the maximum values frightening high.
| Metric | Min | Max | Median | 90th Percentile |
|---|---|---|---|---|
| Start Render | 1,765ms | 8,130ms | 4,617ms | 5,788ms |
| Visually Complete | 4,604ms | 35,096ms | 7,475ms | 21,432ms |
| Speed Index | 3729 | 16230 | 6171 | 10144 |
| Weight | 273kb | 10,385kb | 905kb | 1,553kb |
| Requests | 14 | 308 | 61 | 151 |
Most of the time, AMP’s performance is relatively predictable. However, the numbers also showed that because a page is a valid AMP document, that is not a 100% guarantee that the site will be fast or lightweight. As with pages built with any technology, it’s entirely possible to build an AMP document that is slow and heavy.
Any claim that AMP ensures a certain level of performance depends both on how forgiving you are of the extremes, and on what your definition of “performant” is. If you were to try and build your entire site using AMP, you should be aware that while it’s not likely to end up too bloated, it’s also not going to end up blowing anyone’s mind for its speed straight of the box. It’s still going to require some work.
At least that’s the case when we’re talking about the library itself. Perhaps the AMP cache will provide a bit of a boost.
How well does AMP perform when the library is served using the AMP cache?
The AMP library itself helps, but not to the degree we would think. Let’s see if the Google cache puts it over the top.
The Google AMP Cache is a CDN for delivering AMP documents. It caches AMP documents and—like most CDN’s—applies a series of optimizations to the content. The cache also provides a validation system to ensure that the document is a valid AMP document. When you see AMP served, for example, through Google’s search carousel, it’s being served on the Google AMP Cache.
I ran the same 50 pages through WebPagetest again. This time, I loaded each page from the Google AMP CDN. Pat Meenan was kind enough to share a script for WebPagetest that would pre-warm the connections to the Google CDN so that the experience would more closely resemble what you would expect in the real world.
logdata 0
navigate https://cdn.ampproject.org/c/www.webpagetest.org/amp.html
logdata 1
navigate %URL%
When served from the AMP Cache, AMP pages get a noticeable boost in performance across all metrics.
| Metric | Min | Max | Median | 90th Percentile |
|---|---|---|---|---|
| Start Render | 1,427ms | 4,828ms | 1,933ms | 2,291ms |
| Visually Complete | 2,036ms | 36,001ms | 4,924ms | 19,626ms |
| Speed Index | 1966 | 18677 | 3277 | 9004 |
| Weight | 177kb | 10,749kb | 775kb | 2,079kb |
| Requests | 13 | 305 | 53 | 218 |
Overall the benefits of the cache are pretty substantial. On the high-end of things, the performance is still pretty miserable (the slightly higher max’s here mostly have to do with differences in the ads pulled in from one test to another). But that middle range where most of the AMP documents live becomes faster across the board.
The improvement is not surprising given the various performance optimizations the CDN automates, including:
- Caching images and fonts
- Restricting maximum image sizes
- Compressing images on the fly, as well as creating additional sizes and adding srcset to serve those sizes
- Uses HTTP/2 and HTTPS
- Strips out HTML comments
- Automates inclusion of resource hints such as
dns-prefetchandpreconnect
Once again, it’s worth noting that none of these optimizations requires that you use AMP. Every last one of these can be done by most major CDN providers. You could even automate all of these optimizations yourself by using a build process.
I don’t say that to take away from Google’s cache in any way, just to note that you can, and should, be using these same practices regardless of if you use AMP or not. Nothing here is unique to AMP or even the AMP cache.
How well does AMP perform compared to the canonical article?
So far we’ve seen that the AMP library by itself ensures a moderate level of performance and that the cache takes it to another level with its optimizations.
One of the arguments put forward for AMP is that it makes it easier to have a performant site without the need to be “an expert”. While I’d quibble a bit with whether labeling many of the results I found “performant”, it does make sense to compare these AMP documents with their canonical equivalents.
For the next round of testing, I found the canonical version of each page and tested that as well, under the same conditions. It turns out that while the AMP documents I tested were a mixed bag, they do out-perform their non-AMP equivalents more often than not (hey publishers, call me).
| Metric | Min | Max | Median | 90th Percentile |
|---|---|---|---|---|
| Start Render | 1,763ms | 7,469ms | 4,227ms | 6,298ms |
| Visually Complete | 4,231ms | 108,006ms | 20,418ms | 54,546ms |
| Speed Index | 3332 | 45362 | 8152 | 21495 |
| Weight | 251kb | 11,013kb | 2,762kb | 5,229kb |
| Requests | 24 | 1743 | 318 | 647 |
Let’s forget the Google cache for a moment and put the AMP library back on even footing with the canonical article page.
Metrics like start render and Speed Index didn’t see much of a benefit from the AMP library. In fact, Start Render times are consistently slower in AMP documents.
That’s not too much of a surprise. As mentioned above, AMP documents use the AMP JS library to handle a lot of the optimizations and resource loading. Anytime you rely on that much JavaScript for the display of your page, render metrics are going to take a hit. It isn’t until the AMP cache comes into play that AMP pulls back ahead for Start Render and Speed Index.
For the other metrics though, AMP is the clear winner over the canonical version.
Improving performance….but for who?
The verdict on AMP’s effectiveness is a little mixed. On the one hand, on an even playing field, AMP documents don’t necessarily mean a page is performant. There’s no guarantee that an AMP document will not be slow and chew right through your data.
On the other hand, it does appear that AMP documents tend to be faster than their counterparts. AMP’s promise of improved distribution cuts a lot of red tape. Suddenly publishers who have a hard time saying no to third-party scripts for their canonical pages are more willing (or at least, made to) reduce them dramatically for their AMP counterparts.
AMP’s biggest advantage isn’t the library—you can beat that on your own. It isn’t the AMP cache—you can get many of those optimizations through a good build script, and all of them through a decent CDN provider. That’s not to say there aren’t some really smart things happening in the AMP JS library or the cache—there are. It’s just not what makes the biggest difference from a performance perspective.
AMP’s biggest advantage is the restrictions it draws on how much stuff you can cram into a single page.
For example. here are the waterfalls showing all the requests for the same article page written to AMP requirements (the right) versus the canonical version (the left). Apologies to your scroll bar.
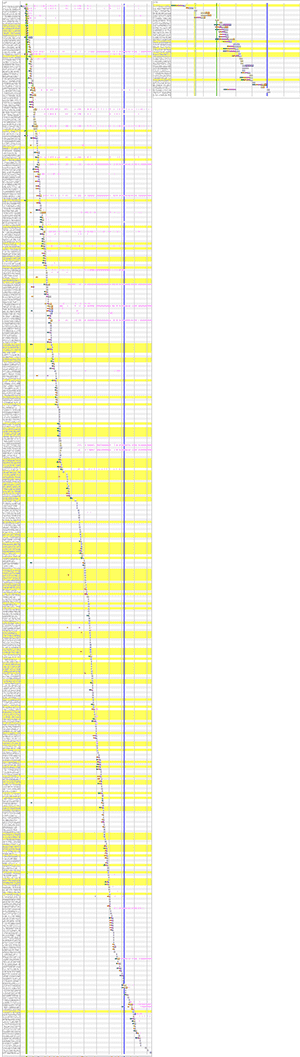
Comparing the waterfalls for the canonical version of an article (left) and AMP version (right). AMP’s restrictions make for a lot fewer requests.
The 90th percentile weight for the canonical version is 5,229kb. The 90th percentile weight for AMP documents served from the same origin is 1,553kb— a savings of around 70% in page weight. The 90th percentile request count for the canonical version is 647, for AMP documents it’s 151. That’s a reduction of nearly 77%.
AMP’s restrictions mean less stuff. It’s a concession publishers are willing to make in exchange for the enhanced distribution Google provides, but that they hesitate to make for their canonical versions.
If we’re grading AMP on the goal of making the web faster, the evidence isn’t particularly compelling. Every single one of these publishers has an AMP version of these articles in addition to a non-AMP version.
Every. Single. One.
And for more often than not, these non-AMP versions are heavy and slow. If you’re reading news on these sites and you didn’t click through specifically to the AMP library, then AMP hasn’t done a single thing to improve your experience. AMP hasn’t solved the core problem; it has merely hidden it a little bit.
Time will tell if this will change. Perhaps, like the original move from m-dot sites to responsive sites, publishers are still kicking the tires on a slow rollout. But right now, the incentives being placed on AMP content seem to be accomplishing exactly what you would think: they’re incentivizing AMP, not performance.